
Последние публикации в коллективном блоге:Интернет-порталы, которые помогут вам успешно сдать ЕГЭ. 1 / Автор: MiriadaЕсли бы вы инвестировали 00 в Amazon 10 лет назад, вот сколько у вас было бы сейчас 2 / Автор: admin Методические рекомендации для выпускников по самостоятельной подготовке к ЕГЭ 2 / Автор: admin В Минпросвещения допустили повторный перенос даты сдачи ЕГЭ 1 / Автор: admin ЕГЭ не отменят из-за коронавируса, но проведут позже 1 / Автор: admin Рособрнадзор будет выявлять нарушения во время ЕГЭ 2020 с помощью нейросетей 1 / Автор: admin ФИПИ опубликовал проекты контрольных измерительных материалов ЕГЭ-2020, существенных изменений нет 4 / Автор: admin Рособрнадзор проанализировал поступившие предложения по совершенствованию ЕГЭ 2 / Автор: admin Посещаемые разделы форума: ЕГЭ 2021, ВУЗы России Последние обсуждаемые темы на форуме:Детские игровые комплексы 0 / Раздел: Помогаем друг другуМягкая кровать без изголовья 2 / Раздел: Помогаем друг другу Очень нужно купить права на трактор 0 / Раздел: Помогаем друг другу кто знает бактерицидные лампы где можно приобрести? 2 / Раздел: Помогаем друг другу мне нужен магазин со стройматериалами 3 / Раздел: Помогаем друг другу Можно ли накрутить голосование в конкурсе? 4 / Раздел: Помогаем друг другу Управление медиафайлами 0 / Раздел: Помогаем друг другу Скажите, пожалуйста, вот в маршрутках в которых мы ездим 3 / Раздел: ВУЗЫ РОССИИ Изучение итальянского языка 5 / Раздел: Помогаем друг другу |
|
|
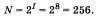 Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т. д.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т. д.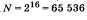 различных символов.
различных символов.